성능 모니터링
![]() Enterprise 플랜에서 사용 가능
Enterprise 플랜에서 사용 가능
![]() Cloud 와 self-hosted 배포판
Cloud 와 self-hosted 배포판
이 기능은 레거시 Mattermost Enterprise Edition E20에서도 사용할 수 있습니다.
성능 모니터링 지원을 통해 Mattermost 서버는 대규모 엔터프라이즈 배포의 시스템 상태를 추적하여 Prometheus 와 Grafana 와 통합하여 시스템 상태를 추적할 수 있습니다. 이러한 통합은 여러 Mattermost 서버에서 데이터 수집을 지원하며, 특히 Mattermost를 고가용성 모드로 실행 중인 경우 매우 유용합니다. 시스템 상태 추적 후에는 Grafana 대시보드에서 성능 경고를 설정할 수 있습니다 .
Note
Prometheus와 Grafana를 Mattermost와 동일한 서버에 설치할 수 있지만, 이 통합들을 별도의 서버에 설치하고 Prometheus를 Mattermost 및 다른 연결된 서버에서 모든 메트릭을 가져오도록 구성하는 것이 좋습니다.
Prometheus 설치
Prometheus용 프리컴파일된 이진 파일을 다운로드 합니다. Darwin, Linux, Windows를 포함한 여러 인기있는 배포판에 대한 바이너리가 제공됩니다. 설치 지침은 Prometheus 설치 가이드 를 참조하십시오.
prometheus.yml이라는 Prometheus 구성 파일에서 다음과 같은 설정이 권장됩니다.
# 내 전체 구성
global:
scrape_interval: 60s # 기본적으로 타겟을 15초마다 긁어옵니다.
evaluation_interval: 60s # 기본적으로 타겟을 15초마다 긁어옵니다.
# 긁어오기 타임아웃은 전역 기본값(10초)으로 설정됩니다.
# 외부 시스템(연합, 원격 저장, Alertmanager)과 통신할 때 모든 시계열이나 경고에 이러한 레이블을 첨부합니다.
external_labels:
monitor: 'mattermost-monitor'
# 규칙을 한 번 로드하고 전역 'evaluation_interval'에 따라 정기적으로 평가합니다.
rule_files:
# - "fi.rules"
# - "second.rules"
# 정확히 한 지점을 긁어올 수 있는 스크레이퍼 구성:
# 여기서는 Prometheus 자체입니다.
scrape_configs:
# 이 작업 이름은이 구성에서 긁어온 모든 타임 시계열에 레이블로 `job= <job_name>` 을 추가합니다.
- job_name: 'prometheus'
# 전역 기본값을 재정의하고 이 작업에서 타겟을 매 5초마다 긁어올 수 있습니다.
# 스크래핑 간격: 5초
# 메트릭 경로는 기본적으로 '/metrics'
# 스키마는 기본적으로 'http'입니다.
static_configs:
- targets: [" <hostname1>: <port>", " <hostname2>: <port>"]
<hostname1>: <port>매개변수를 Mattermost 호스트 IP 주소와 포트로 대체하여 데이터를 긁어옵니다. 이는 HTTP를 사용하여/metrics에 연결됩니다.Mattermost 시스템 콘솔에서 환경 > 성능 모니터링 으로 이동하여 성능 모니터링 활성화 를 참으로 설정 한 다음 청취 주소 를 지정하고 저장 을 선택합니다. 자세한 내용은 구성 설정 을 참조하십시오.
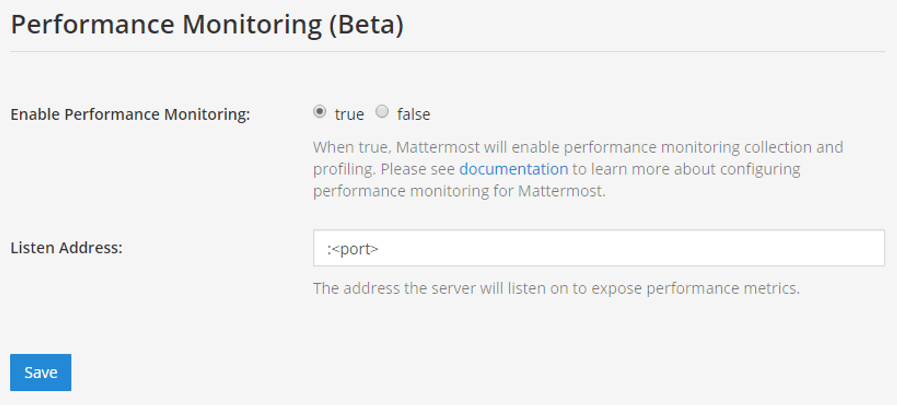
서버가 실행 중인지 테스트하려면
<ip>: <port>/metrics로 이동합니다.
Note
HTTP를 사용하여 /metrics 에 연결하려면 Mattermost 엔터프라이즈 라이선스가 필요합니다.
마지막으로
vi prometheus.yml을 실행하여 Prometheus 구성을 완료합니다. Prometheus 서비스를 시작하려면 Prometheus에서 제공하는 포괄적인 가이드를 확인하십시오 .서비스가 시작되면
<localhost>: <port>/graph에서 데이터에 액세스할 수 있습니다. Prometheus 서비스를 사용하여 그래프를 만들 수 있지만, 우리는 Grafana에서 메트릭 및 분석 대시보드를 만드는 데 초점을 맞출 것입니다.
Note
문제 해결 팁에 대해서는 Prometheus FAQ 페이지를 확인하십시오 .
Grafana 설치
Ubuntu 또는 Debian에 대한 Grafana용 프리컴파일된 바이너리를 다운로드 합니다. Redhat, Windows 및 Mac을 포함한 다른 배포판에 대한 바이너리도 사용할 수 있습니다. 설치 지침은 Grafana 설치 가이드 를 참조하십시오.
Grafana 패키지는 서비스로 설치되므로 서버를 실행하기 쉽습니다. 더 많은 정보를 보려면 설치 가이드를 참조하십시오 .
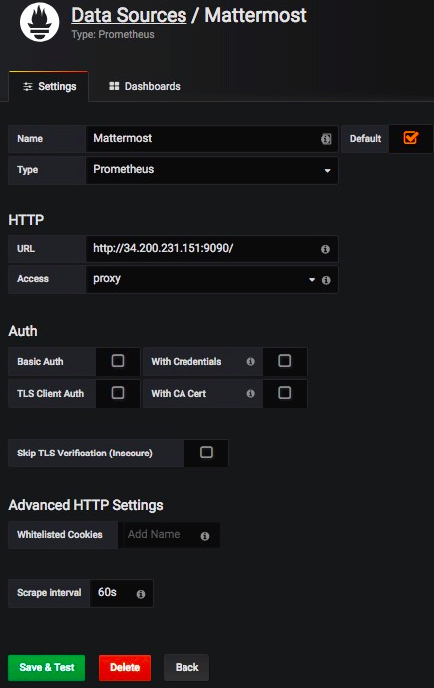
기본 HTTP 포트는
3000이고 기본 사용자 이름과 암호는admin입니다.아래 스크린샷에 정의된 것과 같이 다음과 같은 설정으로 Mattermost 데이터 소스를 추가하십시오.
Note
문제 해결 팁에 대해서는 Grafana 문제 해결 페이지를 확인하십시오
사용자 가이드 및 자습서에 대해서는 Grafana 설명서를 확인하여 더 많이 배우십시오 .
시작하기
시작할 수 있도록, Grafana에서 공유되는 세 개의 샘플 대시보드를 다운로드할 수 있습니다:
Mattermost 성능 모니터링 v2 : 애플리케이션, 클러스터, 작업 서버 및 시스템 메트릭을 포함한 성능 모니터링에 대한 자세한 차트를 포함합니다.
Mattermost Collapsed Reply Threads 메트릭 : 접힌 답글 스레드 기능과 관련된 쿼리에 대한 자세한 메트릭을 포함합니다.
Mattermost 성능 KPI 메트릭 : 성능 및 시스템 상태를 모니터링하는 데 중요한 주요 메트릭을 포함합니다.
Mattermost 성능 모니터링 (추가 메트릭) : 이메일 발송 또는 파일 업로드와 같은 추가 메트릭을 포함하여 일부 배포에서 모니터링이 중요할 수 있습니다.
UI 또는 HTTP API에서 Grafana 대시보드를 가져오는 방법에 대한 이 가이드 를 참조하십시오.
통계
Mattermost는 Prometheus와 Grafana와 통합하여 다음과 같은 성능 모니터링 통계를 제공합니다.
사용자 지정 Mattermost 메트릭
다음은 시스템 성능을 모니터링하는 데 사용할 수 있는 사용자 정의 Mattermost 메트릭 목록입니다.
API 메트릭
mattermost_api_time: 특정 API 핸들러를 실행하는 데 걸린 총 시간(초).
캐싱 메트릭
mattermost_cache_etag_hit_total: 특정 캐시에 대한 총 ETag 캐시 히트 횟수.mattermost_cache_etag_miss_total: API 호출에 대한 총 ETag 캐시 미스 횟수.mattermost_cache_mem_hit_total: 특정 캐시에 대한 총 메모리 캐시 히트 횟수.mattermost_cache_mem_invalidation_total: 특정 캐시에 대한 총 메모리 캐시 무효화 수mattermost_cache_mem_miss_total: 특정 캐시에 대한 전체 캐시 미스 수
위의 메트릭을 사용하여 ETag 및 메모리 캐시 적중률을 시간과 함께 계산할 수 있습니다.
클러스터 메트릭
mattermost_cluster_cluster_request_duration_seconds: 노드간 클러스터 요청의 총 기간(초)mattermost_cluster_cluster_requests_total: 노드간 요청의 총 수mattermost_cluster_event_type_totals: 어떠한 타입을 위해 전송된 클러스터 요청의 총 수
데이터베이스 메트릭
mattermost_db_master_connections_total: 마스터 데이터베이스에 대한 연결 총 수mattermost_db_read_replica_connections_total: 모든 읽기 레플리카 데이터베이스에 대한 연결 총 수mattermost_db_search_replica_connections_total: 모든 검색 레플리카 데이터베이스에 대한 연결 총 수mattermost_db_store_time: 주어진 데이터베이스 저장 메소드 실행에 대한 총 시간(초)mattermost_db_replica_lag_abs: 바이널로그 거리/트랜잭션 큐 길이를 기반으로 한 절대적인 지연 시간mattermost_db_replica_lag_time: 레플리카가 따라잡는 데 걸리는 시간
데이터베이스 연결 메트릭
max_open_connections: 데이터베이스에 대한 최대 열린 연결 수open_connections: 사용 중 및 아이들 상태인 설정된 연결 수in_use_connections: 현재 사용 중인 연결 수idle_connections: 아이들 상태인 연결 수wait_count_total: 대기한 총 연결 수wait_duration_seconds_total: 새 연결을 기다리는 데 블록된 총 시간max_idle_closed_total: 최대 아이들 연결 수가 도달하여 닫힌 총 연결 수max_idle_time_closed_total: 연결 최대 아이들 시간이 설정되어 닫힌 총 연결 수max_lifetime_closed_total: 연결 최대 수명이 설정되어 닫힌 총 연결 수go_goroutines는 고루틴 개수에 사용됩니다go_gc_duration_seconds은 가비지 수집 지속 시간에 사용됩니다go_memstats_heap_objects은 힙 상의 객체 추적에 사용됩니다
러타임 프로파일링 설정 방법을 알아보려면 pprof package Go documentation 을 참조하세요. 또한 ip:port 페이지를 방문하여 설명과 함께 완전한 메트릭스 목록을 볼 수 있습니다.
Note
HTTP를 사용하여 /metrics 에 연결하려면 Mattermost Enterprise 라이선스가 필요합니다.
활성화된 경우 프로파일러를 실행할 수 있습니다.
go tool pprof http://localhost: <port>/debug/pprof/profile
여기서 localhost 를 서버 이름으로 바꿀 수 있습니다. 프로파일링 보고서는 다음 위치에서 사용할 수 있습니다:
CPU 프로파일링을 위한
/debug/pprof/profile명령줄 프로파일링을 위한
/debug/pprof/cmdline/심볼 프로파일링을 위한
/debug/pprof/symbol/고루틴 프로파일링을 위한
/debug/pprof/goroutine/힙 프로파일링을 위한
/debug/pprof/heap/스레드 프로파일링을 위한
/debug/pprof/threadcreate/블록 프로파일링을 위한
/debug/pprof/block/
자주 묻는 질문
차트 레이블이 왜 식별하기 어렵습니까?
서버 필터 및 범례에 사용된 차트 레이블은 기계의 호스트 이름을 기반으로 합니다. 호스트 이름이 유사하면 레이블을 식별하기 어려울 수 있습니다.
기계에 보다 구체적인 호스트 이름을 설정하거나 relabel_config 를 사용하여 Prometheus configuration 에서 표시 이름을 변경할 수 있습니다.













